
This blog is originally post on https://blog.sahrohit.com.np/posts/plane-sweep-parallel and distributed across platforms for more reach. The original paper of this paper summary is available here.
There are two algorithms presented in the paper one is HMAL, and another is Per Segment Sweep Line algorithm. HMAL is limited by synchronization requirement and number of threads allowed in a single GPU grid cell. The other is the PSSL algorithm where it addresses the drawback of the HMAL by using dynamic parallelism. The PSSL algorithm is fast, memory efficient and easier to implement than other competing approaches.
HMAL utilizes processing cores to function as a hardware representation of the active list data structure,containing list segments encountered by the sweep line.The drawback of the HMAL algorithm is the synchronization requirement, it is limited by the maximum number of threads allowed in a single GPU grid cell (currently 1024 threads). Second Algorithm used in this paper is the Per Segment Sweep Line (PSSL) algorithm. It addresses the drawbacks of the HMAL algorithm by eliminating the indeed for synchronization primitives in the GPU kernels, and thus eliminating the limitations of constraining the number of threads to a single thread block. It achieves these improvements by taking advantage of dynamic parallelism. PSSL is easy to implement, fast and memory efficient compared to competing approaches.
Related Work
Serial Plane Sweep Algorithm
Once the sweep line encounters the left endpoint of the line segment, the line segment will be added to the list, and when the right endpoint of the line segment is added to the list it is removed from the active.
Grid based Algorithm
The algorithm treats each grid cell as a separate unit of work for a processing unit by testing each line segment for intersections against all other line segments on the same grid. Polygons with high line segment count in a relatively small area (high-density), will result in grid cells requiring large numbers of comparisons, leading to unbalanced workloads for processing units.
Two-level Grid based Algorithm
In this algorithm, the grid is subdivided again into sub grids if the number of line segments in a grid exceeds a user-specified threshold.
Neighbor finding Reduction Variation of Parallel Sweep Line Algorithm
This algorithm generates events for each endpoint of a line segment and each found intersection point. The initial endpoint events are processed in parallel first. The intersections that are found during the processing of the original endpoints generate new events.
Line Segment Filtering PSCMBR
PSCMBR is a combination of PolySketch (used to find a Minimum Bounding Rectangle (MBR) around a predetermined number of line segments, called a tile) and CMBR (Common minimum bounding rectangle). PolySketch filters for overlapping tiles and CMBR of the tiles refines the search for candidate line segments that intersect.
These are five different types of line segment algorithms that do already exist. The results and time complexity of these algorithms vary and these are also considered for benchmarking and comparing the result of the proposed algorithm.
Preliminaries
List of lines sorted in X-axis forming complex regions. If the segments do not form complex regions (self-intersecting regions or regions without a closed loop) the algorithm will still run to completion. The line segments are generated using a python script.The generated line segments are not generated in sorted order, as sorting these lines are also a part of the algorithm and time complexity of sorting is also considered in the final algorithm
The input data is not sorted and time taken to sort is also considered a part of the algorithm.
Hardware Materialized Active List
The main difference is that of handling the active list. In traditional sweep line algorithms when the left endpoint of a segment is encountered it is entered into the active list and when the right endpoint of the line segment is encountered, it is removed from the active list.
Now since the list is sorted, the newly inserted line segment only checks its neighboring segments in the active list of intersections.
An imaginary sweep line moves across the plane from left to right. As the sweep line encounters new line segments, it is added to the hardware active list and processed for intersections and topology.
When the left endpoint of the segment is encountered, a thread will be assigned. Then this new added segment will be checked for intersection with all the existing threads in parallel. Thus, the active list is itself materialized into the hardware. This removes the logarithmic lookup time for a central tree-based active list. We need to make sure that the number of active line segments doesn’t exceed the number of available CUDA processor cores.
If the x value of the left endpoint is larger than the right endpoint of the segment in the hardware active list. The thread will notice and free itself, automatically removing itself from the active hardware list.
At the end of each loop, the processing threads must be synchronized, to make sure all threads are using the current line segment and all are testing the current line segment for intersections.
The implementation is limited to the maximum active list size of 1024 due to the block level synchronization. The size of the active list for N number of line segments is roughly sqrt(N). So, this algorithm can process 1M total line segments for two polygons.
The active list is actually threads, and when the left endpoint of a line segment is encountered, it is assigned a thread and then it looks for intersection on all items of the active list on their respective threads and stores the result. Then, the right endpoint of the line segment is encountered and the thread is cleared. This makes sure that when the sweep line is moved, it only checks for the intersection in the active list.The limitation of this approach is the maximum size of the active list. Due to the block level synchronization, the maximum size of the active list can be 1024, and hence it can roughly process 1M line segments of two polynomials at once.
Per Segment Sweep Line Algorithm
This algorithm will test line segments, as if encountered by a per-segment sweep line. The intersection tests will be held off for later but the pairing of the line segments is computed first.
Once the pairing of the line segments has been calculated, then a separate dynamic thread will be launched to perform the intersection tests. Since the pairing and intersection happen separately, these are not constrained as HMAL was.
The endpoints are sorted using their x-value, y-value, segmentID and left-right flag using standard parallel sort. The left-right endpoint is used to represent the left endpoint (value of 1) or right endpoint (value of 0) of the line segment.
Test Count Values(TCVs) (number of intersection tests for each line) are calculated.
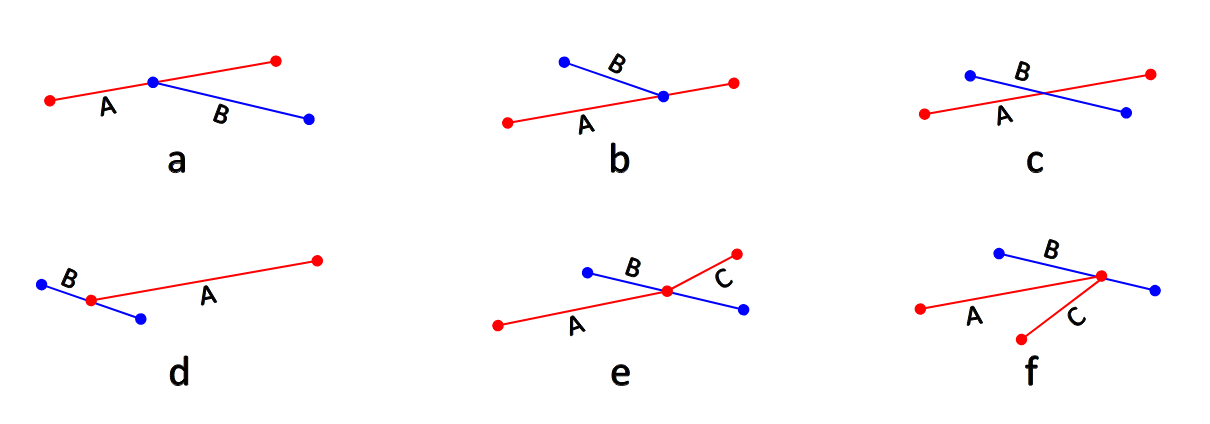
Threads are launched based on the worklist created in the previous step. Then the possible intersections are calculated based on the left-most endpoint. This is done to prevent the repetition of the intersection point calculation. As in Fig(a,b,c) these are the types of intersection calculated for line segment A. Fig (d) type of intersection will be calculated under line segment B. Fig (e) type of intersection will be calculated by line segment B because the rightmost endpoint of the line segment A falls in between line segment B. Fig (f) type of intersection is also calculated by line segment B because A and C don't fully cross segment B.
Once the intersection points are found, the line segment will be broken down and the interior above and interior below data tags will be updated on each line segment.
First the TCVs are calculated by sorting each line by features and also number of intersections are calculated. Then worker threads are launched based on the number of intersections. Then based on the type of intersection the intersections are calculated in order to prevent the repeated calculations. Then the line segments are broken at intersection points and the data is updated.
Algorithm Analysis
HMAL Time Complexity
Sorting of Line Segments: O (N log N)
Detecting Intersections: O(N)
Sorting the number of intersection: O(k log k)
Breaking of Line Segment: O(k)
Total: O(N log N + k log k).
PSSL Time Complexity
Creation of Stencils and determination of intersection tests: O(N)
PSSL Algorithm: O(N)
Breaking of Line Segment: O(k log k)
Update Topology Flags: O(k)
Total: O(N log N + k log k).
The time complexity of both the algorithms is very similar and to be O(N log N + k log k). The main difference is that the HMAL algorithm is limited to the maximum block size of the CUDA threads whereas the PSSL algorithm isn’t.
Experimental Results
Each test is performed 5 times and average of that is taken. The PS-ACC algorithm was not tested as the source code for this program was not available. (Despite being quadratic, PS-ACC performs way better)
By far the best performance is given by PSSL-CPU because the size of the dataset is small (10K to 80K lines). PSSL-GPU lacks behind by an order of magnitude due to the data transfer to/from PGU and kernel launch overheads. This shows that the PSSL-CPU can be used in database applications like PostGIS.
Their own implementation of sweep line algorithm was used instead in order to address the known sensitivity of the number precisions and rounding errors. In the Parks/Counties dataset, the SSL enters an infinite loop due to the arithmetic precision errors.
The PSSL-GPU performs at linear and sublinear times due to the maximum size of the list never exceeding the number of processing cores.
PSSL didn’t struggle either on CPU or GPU, but it is sensitive to the density of the intersections.
PSCMBR is the algorithm that uses geometric overlay instead of joins to find the intersection of the polygon. This cannot be entirely compared with the PSSL algorithm as PSSL performs joins operation but PSCMBR does polygon overlay. In the results, PSCMBR does perform better on datasets with high density where PSSL lacks.
Each test is run 5 times and their average time for the results is taken. The algorithms are tested both on generated dataset as well as real world datasets. The HAML algorithm didn’t run on all tests due to the block synchronization requirements. PSSL did perform better on all tests and showed little bit of struggle while performing operation on dense datasets. The PSSL algorithm is also compared with PSCMBR.